
How to use the latest web frameworks and self-hosted micro-services to turn a static website into an observable, collaborative and searchable blog.
Context
I never really had a blog nor felt the necessity to have one. That changed recently as I wanted to gain online visibility and publish some technical articles about the infrastructure I worked on for several years, and for which I started a port from the professional to the private space: IT Sufficient.
Frameworks frenzy
I never developed full time for the web. I managed to stay updated because the projects that presented themselves were always small enough to be started from scratch, and I could just pick up the most interesting platform of the moment and follow the trends from a comfortable distance.
I started (a long time ago) with Cocoon, used ruby on rails, django, and nodejs. I’ll spare you the details of versions, frameworks of frameworks and tool chains. All of this stretched over a long period of time…
A new kind of static
A blog is exactly the kind of project you can use to discover a new framework, but as I wanted to capitalize on a stunning experience I had a few months earlier, I just picked up instead something I already knew: Gridsome.
I managed to develop this e-commerce site in 2 weeks to sell our things before relocating to France, by just grabbing some templates, study a little of Vue, tailwindcss and follow some tutorials. It was responsive, fully static with a cart management, orders sent by email, and even a back office to follows orders, payments, and update quantities.
After several years of Odoo technical and functional consultancy, I never imagined being able to do that from scratch and without a backend, certainly because we rarely think of the file-system as a real back-end.
I was totally converted to the pertinence of Jamstack from that point and, as I started to draft the layout and the UI for the blog, I had to put everything on pause to organize our new life.
The bus factor
Time flew by with our relocation and when I got back to my blog and Gridsome, I was surprised to see that no revision had been published for quite a long time and that it was still not compatible with Vue 3.
A blog is indeed a small project but a long to midterms one (at least I hope so). I didn’t want a framework with an already low bus factor before even going live.
Svelte
I started to understand the JavaScript fatigue that so much web developers were talking about and from which I was preserved. Furthermore, I started to think that the 6 months obsolescence timeout was no joke in the web development world.
I pulled myself back together and after quickly experimenting Nuxt, I picked, out of curiosity, the most loved web framework: svelte with its companion sveltekit. I did the same a few years back when I tried rust, and once again I was not disappointed.
I found afterward that Josh Collinsworth took quite the same path as mine and described the migration in a more technical way in his blog post Converting from Gridsome to SvelteKit.
What follows is just some newcomer impressions about the framework and a technical description of the blog behind IT Sufficient. It is an introduction to more detailed posts that will be part of this series.
Bright sides
Svelte is a disruptive technology. Let’s look at the bright sides.
Learning material
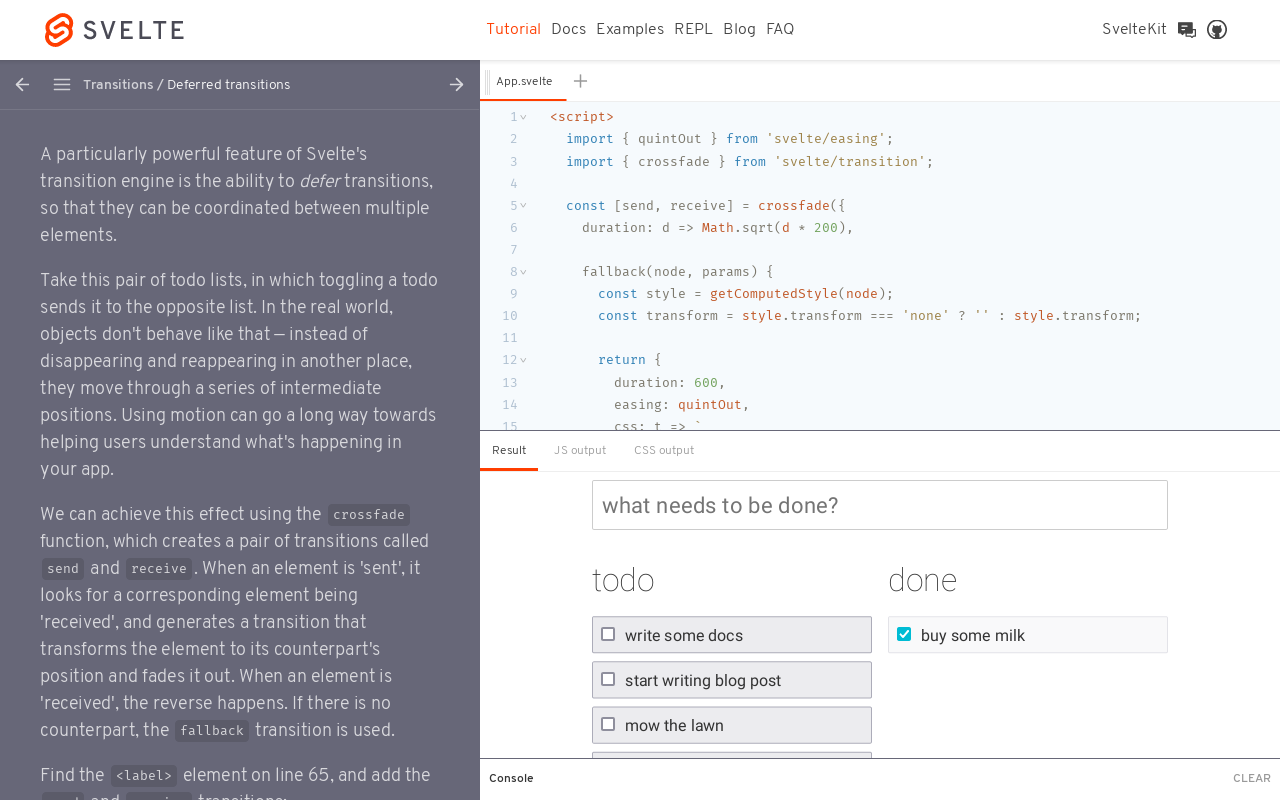
The learning platform for svelte is the best I saw for any web framework so far. You can follow the interactive tutorial online and browse the interactive examples. In just a few hours, and without installing anything, you can grasp the main concepts of the framework. The technical documentation is ok but could probably afford a better navigation system and an integrated search engine.
There are already a lot of good tutorials on how to create a markdown blog with SvelteKit, and I took my inspiration from theses :
- SvelteKit Tutorial: Build a Svelte MDsveX Blog Site
- How I built a blog with Svelte and SvelteKit
- MDSveX and Svelte Kit
- Let’s learn SvelteKit by building a static Markdown blog from scratch
It didn’t take me a lot of time to have a rough proof of concept and see that svelte was different and also the right choice.
No virtual DOM
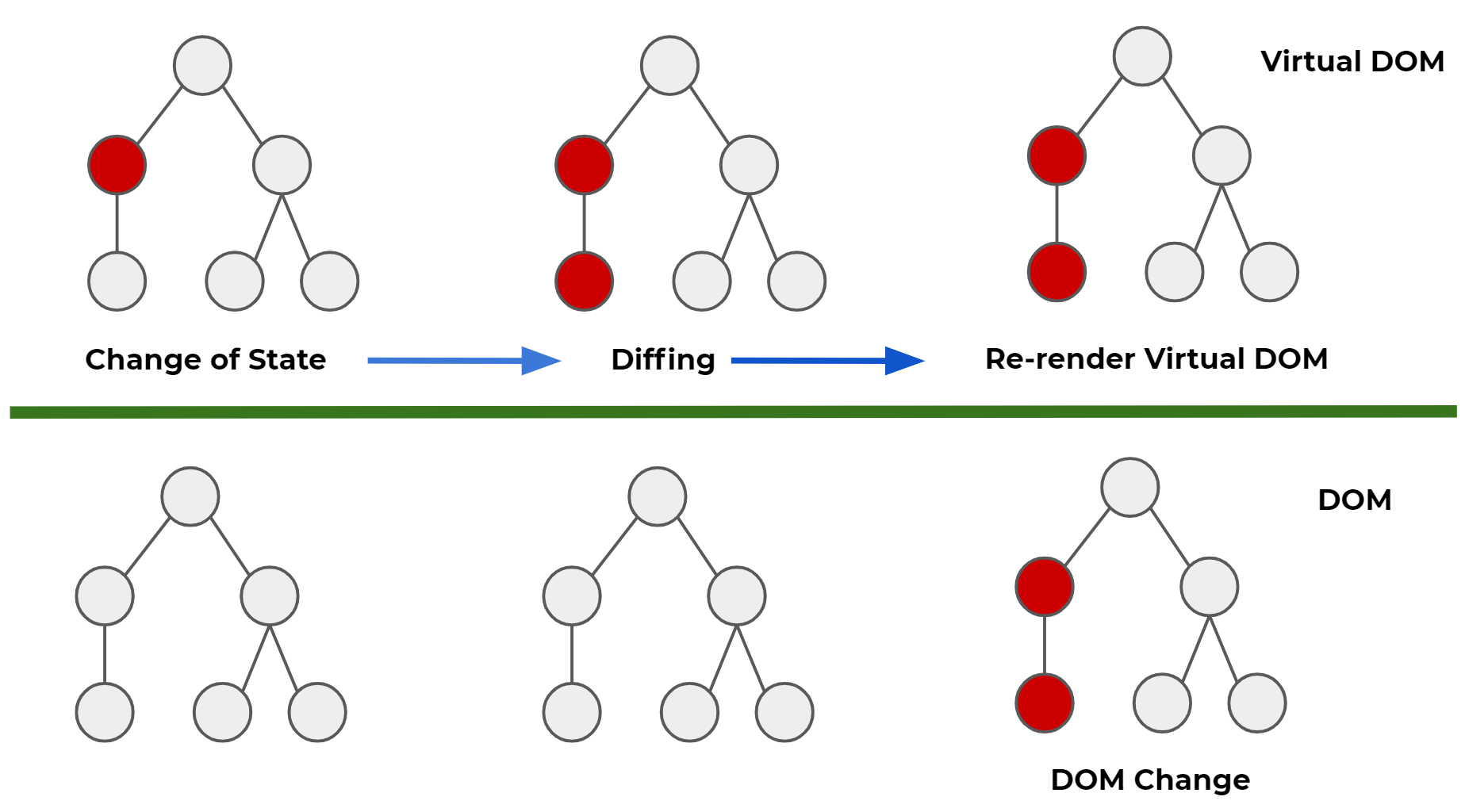
You can read why
Virtual DOM is pure overhead according to
svelte author. After my short incursion into Vue territory this was some really fresh air to me. At
the programming level I deleted a lot of lines from the original code that were just handling corner
cases related to virtual DOM management in Vue (the weird nextTick() dance).
The reactivity code looks much cleaner and straightforward to the point that I don’t see any advantage for virtual DOM anymore. You can probably have some flickering issues because the DOM is updated directly without the kind of double buffer the virtual DOM gives you for free, but you can perfectly optimize your flows, or implement a double buffer yourself for the parts that really need it, without having to pay for the diffing phase overhead.
The resulting code generated from svelte is a lot more compact and faster than with any virtual DOM framework, and I’m sure there is still room for improvements. Without doing anything I got 100% at lighthouse tests.
SSG, SSR, and SPA all in one
Server Side Rendering (SSR) for free was the second good surprise. Even if nowadays this is pretty common with Vue too, this was my fist real experience with the concept.
SvelteKit statically generates the pages like a Server Side Generated (SSG) framework would do, but pages are in fact really close of what they would be if rendered inside the browser after the execution of all the scripts. This JavaScript evaluation, server side, is what makes SSR different from SSG or a Single Page Application (SPA).
On top of that, when a page is fully loaded by the client, an hydration
process update the sections of the page that need to be synchronized (if
any). This hydration process also blurs the frontier between an SPA and an SSG
one. For instance, the route associated to this blog’s index page is defined as
src/routes/blog/[category]/[value]/[page].svelte,
and if you navigate between categories, tags, date, the pages will not be reloaded
but updated like inside an SPA. Now if you land directly (bookmark) on a location
(/blog/categories/development/1) no need to define a route on your web server to
point to the entry point file like you do with an SPA, you have a static file corresponding
to this very location.
We can borrow the term reconciliation that DevOps people like very much to understand better why SSR is a big deal.
If you look at this site, there are some counters that rely on external microservices to show page views ( 505) and number of comments ( 3). Each time the site is generated on the server, SvelteKit takes the current values to generate a plain HTML file, and when the page is fully loaded on the client, a reconciliation process runs in the background to change the counters to their up-to-date values. We have good enough values when the page loads or when there is an outage on external services, and we limit content shifting when values are updated which generally went unnoticed. By scheduling pipelines every day on the CI/CD side, we can also limit the drift. The best of both world.
There are subtle differences between a layout and a component regarding this SPA behavior with SvelteKit. I used at the beginning SvelteKit layouts to share a common layout for the whole site, but I ended using mdsvex layout instead (which is a component), because I wanted the table of contents (represented by a store) to be rendered at the same time as the article. With a SvelteKit layout, the sidebar was empty on SSR side, and you had to wait a few ms to see a table of contents populated by hydration. That also meant that without JavaScript you had no table of content. On top of that mdsvex layout allows you to easily map HTML elements to svelte components, making the use of rehype plugins unnecessary.
SSR is better for SEO because crawlers got the full pages, and it makes your pages appear instantaneously on the client (improves the time to First Contentful Paint).
Progressive enhancement made easy
It may seem useless to develop a website without JavaScript today, but if you think the other way around, there isn’t any good justification to make it mandatory just for reading a bunch of technical articles. Thanks to SSR (and a minimal effort), this blog is perfectly usable without JavaScript and even the navigation is functional. The only thing that is lost is access to microservices (analytics, comments, search), interactivity (dark theme, copy to clipboard, highlighting TOC), and animation on SVG graphics on some articles. No big deal.
Components that need JavaScript are invisible by default (instead of hidden to avoid content shifting) and become visible only when JavaScript is active. With Svelte lifecycle management, you can easily implement progressive enhancement with something like this :
<script>
import { onMount } from 'svelte';
let mounted = false;
onMount(() => {
mounted = true;
})
</script>
<!-- the element is not visible but occupy space in the layout
to avoid content shifting -->
<div class:invisible={!mounted}>
</div>Sometimes you need a different version of an element depending on the fact that JavaScript
is activated or not. In that case you can use hidden class on sibling elements that
occupy the same place to avoid content shifting :
<!-- this is the version when javascript is not enabled -->
<div class:hidden={mounted}>
</div>
<!-- this is the version when javascript is enabled -->
<div class:hidden={!mounted}>
</div>If you look for instance at this page in mobile mode without JavaScript, you will see that the Hamburger icon links to a menu page instead of showing/hiding the side menu.
I found that comparing pages with and without JavaScript during development also helps to better understand Svelte concepts, as you can clearly see the effect of hydration.
Perfect cache system
When using SvelteKit static adapter, each referenced page is pre-rendered and written on the disk. By just relying transparently on the OS IO caching mechanisms (file-system), your static file server can now act as a perfect application cache for free.
SSR and microservices force you to decompose your application into a common part and some variable parts. The common part is what is cached and represents most of the data sent to clients, whereas the variable parts are negligible and even optional for viewing the pages.
If you already tried to implement a cache for a legacy SSG site (Python, PHP, node.js, …), you will certainly agree that the Jamstack + microservices approach is way more coherent, efficient and easier than trying to intercalate memcached between every request and responses with timestamps and checksums (which are error-prone and complex to debug) to invalidate the cache. In the rust world we would have call the implicit cache offered by SvelteKit SSR, a zero cost abstraction.
Building speed
Vite, which is in part responsible for SvelteKit velocity, can also be used with Vue, but coming from Gridsome with its webpack pipelines, it felt like a fresh breeze. On the CI/CD side, the site is fully built and deployed under a minute where it took 5 minutes with Gridsome, and without any compilation issues (node-gyp is erratic on alpine Linux and musl).
Modifications in development mode are nearly instantaneous with no perceptible overhead for using TailwindCSS (thanks to the new JIT mode) and pug.
Easy library integration
Because there is no virtual DOM, you can bind directly a variable to the DOM representation of the
component using the bind:this attribute, or you can define
a foo function that receives the DOM node and use it on your component with the
use:foo attribute. That makes working with vanilla
JavaScript library really easy.
This is for example a simplified integration of simplebar as a svelte component that is used on this blog to change the scroll bar appearance.
src/lib/components/simple-bar.svelte
<script>
import SimpleBar from 'simplebar';
import 'simplebar/dist/simplebar.css';
export let options = {};
let simplebar;
function simpleBar(node) {
simplebar = new SimpleBar(node, options);
return {
destroy() {
simplebar.unMount();
}
};
}
</script>
<div use:simpleBar><slot></slot></div>Fewer dependencies
Svelte seems so simple and straightforward that you quickly start to re-implement functionalities instead of relying on external libraries, for simplicity, readability, and optimization.
I removed for instance vanilla-lazyload because it was
a black box in the sense that you add some class on your images (lazy), rename some attributes
(data-src), and hope it would do the job independently of other functionalities. You end up
calling update() in several places to signal events invisible to lazyload and then start to feel
that a pure svelte implementation would be easier and smarter after-all.
So I ended up using an intersection observer that can be used inside other components (animations, images, comments, …). The component itself is really simple (less than 100 lines) and allowed me to remove the init, update and cleanup code of lazyload.
This is for example a simplified lazyload image component with the intersection observer.
src/lib/components/image.svelte
<script>
import IntersectionObserver from 'svelte-intersection-observer';
export let alt = '';
export let width;
export let height;
export let placeholder;
export let src;
let element;
</script>
<template lang="pug">
IntersectionObserver("{element}" let:intersecting once)
img(
bind:this="{element}"
"{alt}"
"{width}"
"{height}"
src="{intersecting ? placeholder : src}"
)
</template>Challenges
Gridsome is built on top of Vue and a lot of other packages. If I had to build a blog with Vue alone, I would certainly have encountered the same difficulties. In the near future, we will see new frameworks built on top of svelte or SvelteKit integrating those missing features but for now, you need to manually glue things together, and for someone like me who is not a web developer, that was time-consuming.
No data layer
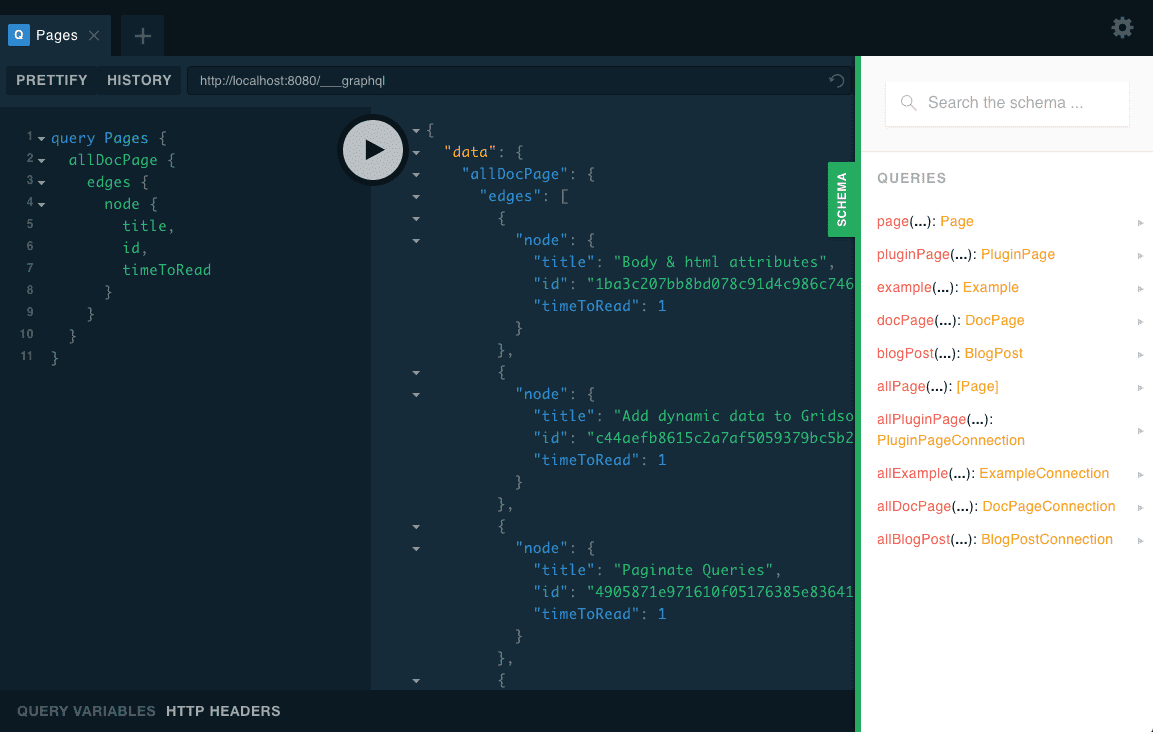
One of the main advantage of Gridsome is to provide a GraphQL layer (even an interactive one during development) abstracted from where the data is coming from (file-system, HTTP, native GraphQL db, …). The data is magically injected in your pages and components with paginated GraphQL requests. When statically rendered, everything turns into JSON for hydration.
With SvelteKit you are alone. You got the frontmatters of your markdown files with the mdsvex component, but you have to group your posts inside JavaScript arrays and dictionaries, represent somehow the relations, fetch what you need in your templates and pages, and manage pagination.
No default image handling
Gridsome is also pretty good at handling images. Drop your pictures in a folder. It optimizes everything and provides a component that lazy load them without even knowing it.
This was probably the most painful part of the migration. The solution I chose is based on vite-image-tools and a npm script to generate some JS files that declare the images to import upfront. Those pictures are then used inside a dedicated Picture component which deal transparently with placeholder, formats and resolutions using an intersection observer.
This is mainly the solution presented by Rodney lab but with multiple images by post and an intersection observer component instead of the external library vanilla-lazyload.
Software stack
Besides the various web frameworks, I chose 3 microservices that give the dynamic aspect of this otherwise static website.
I will describe in future articles the whole on premises infrastructure behind this blog (bare-metal Kubernetes cluster with GitLab, CI/CD and a static server developed in rust, …), but what follows for now is a quick description of its software stack. I will complete with further details in the remaining posts of the present series.
Stylesheets
I was immediately convinced the first time I tried TailwindCSS. I’m not a web designer, and having decent defaults for spaces, typography and colors you can reuse the same way, all over your projects, was a game changer.
Having the style directly in the markup though classes named after the effect they have on the
layout (font-bold, text-center, inline, …) free your mind. Instead of having to construct a
mental model around multiple trees of HTML tags, CSS selectors and files, you have everything under
your eyes. You can copy/paste some HTML, and it will work as is in a totally different context: a
kind of bootsnippet on steroid.
Apart from a few corner cases to avoid too much repetition, semantic CSS is dead to me. You can read CSS Utility Classes and “Separation of Concerns” by Adam Wathan if you want an in-depth justification.
I just purchased the access to tailwindui.com to develop this blog layout.
Widgets
Another great contribution of TailwindCSS author is headless UI which is like its logical extension. I will point you again to a great Adam Wathan post: Renderless Components in Vue.js to understand the what, why and how, but in short, it allows you to decouple the component behavior from its appearance. You focus on the appearance you want, and you get the rest (keyboard navigation, functional behavior, focus, accessibility, …) for free.
As a lot of TailwindUI components use headlessUI, I was relieved the day an unofficial but nevertheless complete svelte port appeared on GitHub: svelte-headlessui. It worked flawlessly so far, and all the UI components on this blog are headless.
Search engine
I was stunned by the effectiveness of the search function on TailwindCSS website. I already saw a few algolia powered sites, but as I started to search extensively among tailwind utility classes, delegating that kind of functionality to an external service started to make a lot of sense. It is, by the way, one of the best integration I ever saw.
I already knew Meilisearch because of the buzz it made in the rust space,
but I thought it would take some tremendous effort to set up everything and learn meilisearch
internals. That what always stopped me with elasticsearch.
I started to play with docs-searchbar.js but found it was too much of a hack to integrate with svelte and tailwind. Nevertheless, I was quite impressed by the scrapper companion of docs-searchbar.js: docs-scrapper. It magically indexed the whole blog by just launching it.
With the data already structured and collected by the scrapper, I just had to focus on developing a headless UI component from scratch with meilisearch-js, and the search functionality was integrated to the blog and inside the CI/CD pipeline in no time.
The only difficulty occurred because of the necessity to set up some
CORS header. This was resolved at the
Kubernetes ingress level (I use contour) by defining an
HTTPProxy resource to inject the missing
headers.
I’ll explain in more details the whole implementation in the 2nd post of this series.
Comments
A blog without the possibility to engage in conversations looks pretty useless to me. disqus was not an option because I didn’t want to rely on any external services to follow IT Sufficient principles. I also didn’t want any solution around interpreted languages (the famous 85% saving on resources with compiled alternatives).
remark42 is fast (written in Go), self-contained (file based bbolt database) and has an extensive API you could theoretically use for reimplementing a pure svelte chatter. I chose the easy path and used the bundled iframe implementation and limited the use of the API to inject comment counters in pages.
I’ll use the 3rd post of this series to explain the integration with most of the details.
Web analytics
As an author, it is important to have some rough analytics about your audience and know which articles are viewed. As for disqus, using Google Analytics was not an option.
I knew some open-sources alternatives existed, but I was also afraid to have to spend too much time to set up everything. plausible didn’t exist the last time I checked. I didn’t fancy the fact that it worked on top of a vm (even if it is BEAM), but I gave it a try anyway. It was really easy to set up, the interface is clean and the reports simple. I’ll probably never choose Google Analytics ever again, specially since it has been declared non GDPR compliant.
There is also an API you can use to inject counters (page views, visitor, …).
The only annoyance I had was with uBlock origin which blocked the plausible script besides coming from my own private domain. It was quickly resolved by renaming and embedding the script in static assets.
In the third post of series we will also see how the integration was done on this blog.
Is this worth ?
As a disruptive technology, svelte will inspire a whole new family of frameworks. Knowing one representative of its kind, even superficially, is good to be able to follow the trends and make the right technical choices at the right time. If only for that reason, it was worth the time invested to learn one more framework.
If I missed all the Gridsome black-boxes at the beginning, I’m feeling now more in control. The solution is simpler, less dependent to JavaScript libraries, and more resilient to their discontinuations.
Next episodes
For the next episodes, I’ll mainly focus on the setup of the microservices. Their interfaces are simple enough to match my superficial understanding of svelte, and this is probably the field where I can better complement all the web experts around that can talk about svelte a lot better than me.
Feel free to ask me anything and give me your feedback, so I can orientate the remaining posts of this series. You are the reason I made all of this in the first place.

Éric BURGHARD